インターネット上の技術・知識を活用してよりよい社会の実現を目指すインターネットサービス企業です。
ファーエンドテクノロジー株式会社

ワールドカップのおかげで寝不足で目がシパシパします。アルゼンチン優勝で泣けてきました(メッッッッシーーーーーー!!!!)。涙のおかげで目が潤ってプラマイゼロです。
こんにちわ。Amazonプロ(自称)の吉岡です。今回はログに関する改善を行ったのでそのことを記事に書きたいと思います。
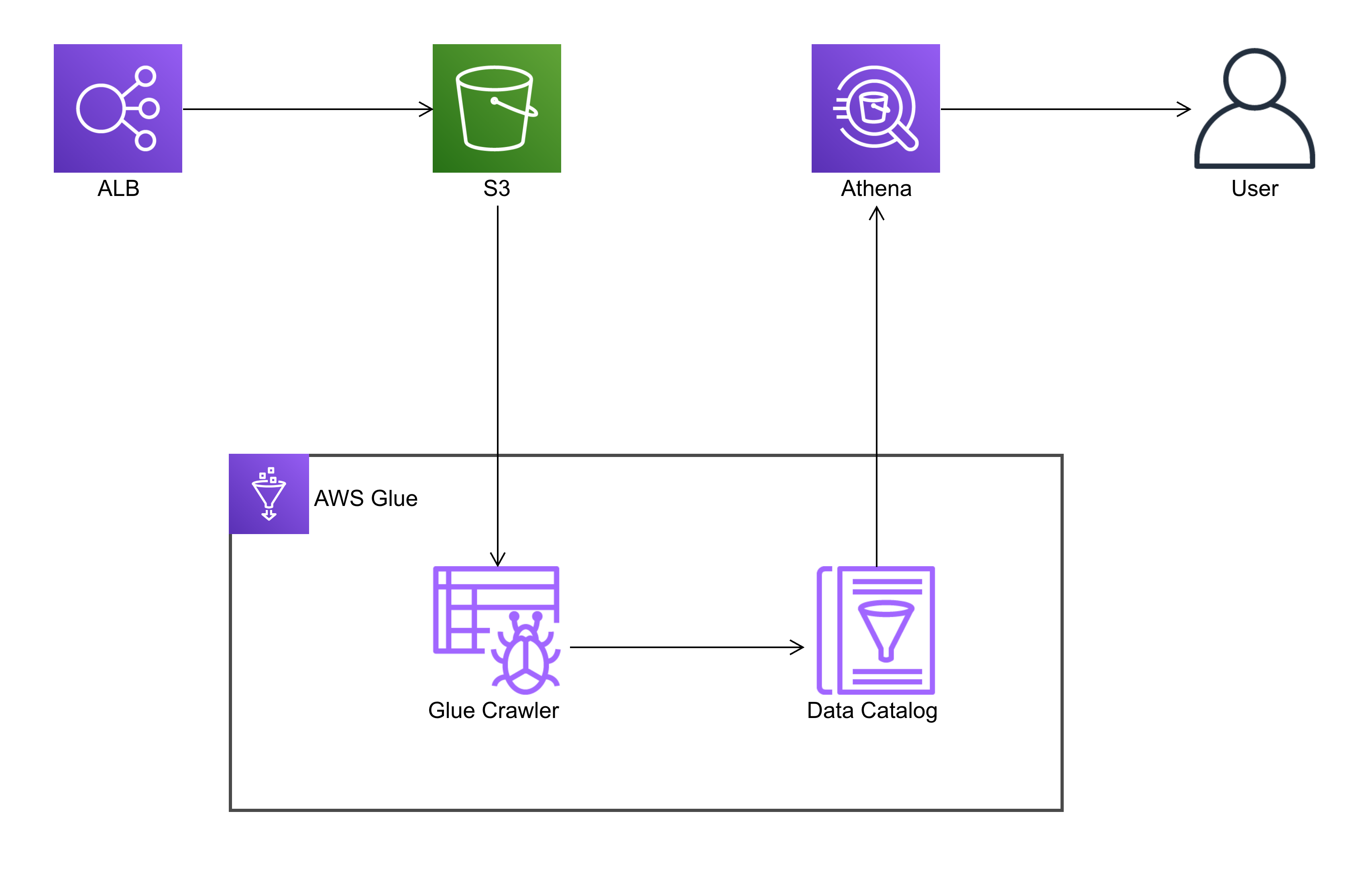
AWS ECS を利用してWEBアプリケーションを公開する場合、Application Load Balancer(以下ALB)をよく利用します。ALBのログはデフォルトでS3に出力することができるのですが、そのままでは扱いづらい(見づらい)ので、今回は Amazon Athena を利用してクエリーで検索できるようにしました。
全体図は以下の通りです。
AWSの設定方法についてご紹介しますが、今回は CDK を利用して設定していきます。
以下のコマンドでベースとなる新しいアプリを作成します。
mkdir my-cdk-app cd my-cdk-app cdk bootstrap cdk init app --language=typescript
コマンドの詳細はこちらを確認してください。
https://docs.aws.amazon.com/ja_jp/cdk/v2/guide/cli.html
初期化が終わりましたら、./lib/my-cdk-app-stack.ts を以下のように変更します。
import { Stack, StackProps } from "aws-cdk-lib"; import { Construct } from "constructs"; import * as glue from "aws-cdk-lib/aws-glue"; import * as s3 from "aws-cdk-lib/aws-s3"; import * as iam from "aws-cdk-lib/aws-iam"; const ALBLogBucketName = "[your bucket name]"; const dbname = "[new database name]"; const awsAccoutnId = "[aws account id]"; const filePath = "/[your alb name]/AWSLogs/[aws account id]/elasticloadbalancing/[reagion]/" export class MyCdkAppStack extends Stack { constructor(scope: Construct, id: string, props?: StackProps) { super(scope, id, props); // ログの保存先(Bucket)の読み込み const ALBLogBucket = s3.Bucket.fromBucketName(this, "existingALBLogBucket", ALBLogBucketName); // ログを保存しているS3のバケットへのアクセス権限を付与したロールを作成します。 const roleForGlueCrawler = new iam.Role(this, "S3AccessForGlueCrawler", { assumedBy: new iam.ServicePrincipal("glue.amazonaws.com"), }); const GlueServiceArn = "arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole"; roleForGlueCrawler.addManagedPolicy( iam.ManagedPolicy.fromManagedPolicyArn(this, "AWSGlueServiceRole", GlueServiceArn) ); roleForGlueCrawler.addToPolicy( new iam.PolicyStatement({ actions: ["s3:GetObject", "s3:PutObject"], effect: iam.Effect.ALLOW, resources: [`${ALBLogBucket.bucketArn}/*`], }) ); // Glue Data Catalog // データカタログを保存するDBを作成します。 const database = new glue.CfnDatabase(this, "newDatabase", { catalogId: awsAccountId, databaseInput: { name: dbname }, }); // クローラーがS3のログを読み込む際のログのパターンを設定します。 const ALBClassifierName = "ALBLog"; const ALBClassifier = new glue.CfnClassifier(this, "GrokForALBLog", { grokClassifier: { name: ALBClassifierName, classification: ALBClassifierName, grokPattern: '%{DATA:type} %{TIMESTAMP_ISO8601:time} %{DATA:elb} %{DATA:client} %{DATA:target} %{BASE10NUM:request_processing_time} %{DATA:target_processing_time} %{BASE10NUM:response_processing_time} %{BASE10NUM:elb_status_code} %{DATA:target_status_code} %{BASE10NUM:received_bytes} %{BASE10NUM:sent_bytes} "%{DATA:request}" "%{DATA:user_agent}" %{DATA:ssl_cipher} %{DATA:ssl_protocol} %{DATA:target_group_arn} "%{DATA:trace_id}" "%{DATA:domain_name}" "%{DATA:chosen_cert_arn}" %{DATA:matched_rule_priority} %{TIMESTAMP_ISO8601:request_creation_time} "%{DATA:actions_executed}" "%{DATA:redirect_url}" "%{DATA:error_reason}" "%{DATA:target_list}" "%{DATA:target_status_code_list}" "%{DATA:classification}" "%{DATA:classification_reason}"' }, }); // クローラーの設定 const s3path = ALBLogBucket.s3UrlForObject() + filePath; const ALBCrawler = new glue.CfnCrawler(this, "ALBCrawler", { name: "ALBLogCrawler", role: roleForGlueCrawler.roleArn, targets: { s3Targets: [{ path: s3path }] }, databaseName: dbname, classifiers: [ALBClassifierName], recrawlPolicy: { recrawlBehavior: "CRAWL_EVERYTHING" }, schemaChangePolicy: { updateBehavior: "UPDATE_IN_DATABASE", deleteBehavior: "DEPRECATE_IN_DATABASE", }, tablePrefix: "alb_log_", schedule: { scheduleExpression: "cron(0 0 * * ? *)", }, configuration: '{"Version": 1.0, "Grouping": {"TableGroupingPolicy": "CombineCompatibleSchemas"}}', }); } }
補足1. 値の設定
以下の値はそれぞれの環境ごとに変更してください。
// ALBのログが保存されているバケット名 const ALBLogBucketName = "[your bucket name]"; // データカタログように新規にDBを作成(任意の名称) const dbname = "[new database name]"; // 利用しているAWS アカウントID(数字) const awsAccoutnId = "[aws account id]"; // ALBのログが保存されているファイルまでのパス(年月日は除く) const filePath = "/[your alb name]/AWSLogs/[aws account id]/elasticloadbalancing/[reagion]/"
補足2. ログのパスとパーティションについて
const filePath = "/[your alb name]/AWSLogs/[aws account id]/elasticloadbalancing/[reagion]/" ... const s3path = ALBLogBucket.s3UrlForObject() + filePath; const ALBCrawler = new glue.CfnCrawler(this, "ALBCrawler", { ... targets: { s3Targets: [{ path: s3path }] }, ... })
ALBのログは自動的に年月日がパス(プレフィックス)として記述されます。
(例: /xxxxxxxxx/AWSLogs/xxxxxxxxx/elasticloadbalancing/ap-northeast-1/2022/12/20/xxxxxx.log.gz)
パスを指定するときにはこちらの年月日 /2022/12/20/ を含まないパスを設定します。年月日でパーティションを分けることで検索速度を早めたりコストを安く抑えることができます。
詳細は以下の公式ページをご確認ください。
補足3. ALB ログと Grok パターンの設定
ALBのログは以下のような形式になっています。
http 2022-06-20T23:57:41.207278Z app/xxxxxxxxxx/e1e09c8e704de3f0 212.192.246.xxx:56214 - -1 -1 -1 301 - 270 328 "GET http://18.180.xx.xxx:80/ HTTP/1.1" "Linux Gnu (cow)" - - - "Root=1-62b10974-52010f0164xxxxxx" "-" "-" 0 2022-06-20T23:57:40.979000Z "waf,redirect" "https://18.180.xx.xxx:443/" "-" "-" "-" "-" "-"
このままの形式ではデータカタログで利用できないので Grok パターンを利用して、ALBのログをデータカタログで使用できる形に変換して解析します。
ALB ログの詳細はこちらをご確認ください。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/load-balancer-access-logs.html
パターンサンプル
'%{DATA:type} %{TIMESTAMP_ISO8601:time} %{DATA:elb} %{DATA:client} %{DATA:target} %{BASE10NUM:request_processing_time} %{DATA:target_processing_time} %{BASE10NUM:response_processing_time} %{BASE10NUM:elb_status_code} %{DATA:target_status_code} %{BASE10NUM:received_bytes} %{BASE10NUM:sent_bytes} "%{DATA:request}" "%{DATA:user_agent}" %{DATA:ssl_cipher} %{DATA:ssl_protocol} %{DATA:target_group_arn} "%{DATA:trace_id}" "%{DATA:domain_name}" "%{DATA:chosen_cert_arn}" %{DATA:matched_rule_priority} %{TIMESTAMP_ISO8601:request_creation_time} "%{DATA:actions_executed}" "%{DATA:redirect_url}" "%{DATA:error_reason}" "%{DATA:target_list}" "%{DATA:target_status_code_list}" "%{DATA:classification}" "%{DATA:classification_reason}"'
パターンについてはこちらのAWS公式ブログを参考にしています。
https://aws.amazon.com/jp/blogs/big-data/catalog-and-analyze-application-load-balancer-logs-more-efficiently-with-aws-glue-custom-classifiers-and-amazon-athena/
コードを修正して保存が終わりましたらデプロイします。(cdk synth は cloudformation テンプレートに変換できるかテストするために実行しています。必須ではありません。)
cdk synth cdk deploy
無事にデプロイが終了されたら、CDKで設定したクローラーが実行される時間が過ぎるのを待ちます。または AWS Glue のクローラーを手動実行します。(マネージメントコンソールから「run crawler」を実行)
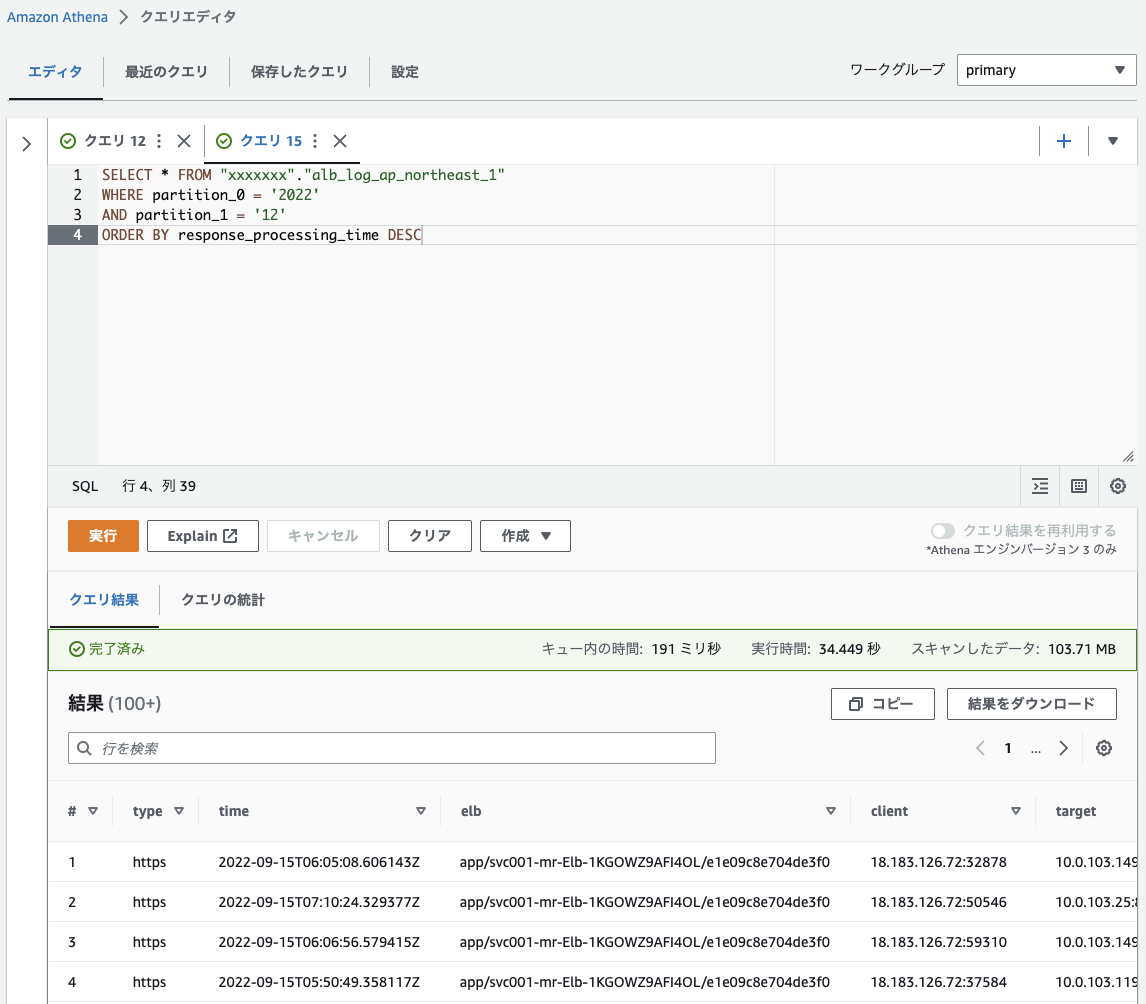
設定が終わりましたら実際にクエリーを発行してログを検索してみます。マネージメントコンソールの Athena の画面からクエリーを実行してみます。
いくつかクエリーの例を記載しておきます。
一覧取得
SELECT * FROM "[your dbname]"."alb_log_ap_northeast_1" limit 10;
status code が4xxのログを取得
SELECT * FROM "[your dbname]"."alb_log_ap_northeast_1" WHERE elb_status_code LIKE '4%' AND partition_0 = '2022' AND partition_1 = '12';
レスポンスに時間がかかったアクセスを時間がかかった順に表示
SELECT * FROM "[your dbname]"."alb_log_ap_northeast_1" WHERE elb_status_code LIKE '4%' AND partition_0 = '2022' AND partition_1 = '12'; ORDER BY response_processing_time DESC
これで期待通りの出力が得られれば設定は完了です。
以上、簡単でしたが ALB のログを Athena で検索できるようにするための設定を紹介させていただきました。今後は Amazon QuickSight を利用してログの可視化をしたいと思っています。こちらのブログがどなたかの参考になれば幸いです。
【スタッフ募集中】
弊社ではAWSを活用したソリューションの企画・設計・構築・運用や、Ruby on Rails・JavaScriptフレームワークなどを使用したアプリケーション開発を行うスタッフを募集しています。採用情報の詳細
弊社での勤務に関心をお持ちの方は、知り合いの弊社社員・関係者を通じてご連絡ください。

|
 AWS CLI の活用例の紹介 AWS CLI の活用例の紹介最近よく使う AWS CLI の便利なコマンドを紹介します。 |

|
 導入事例コンテンツ取材&執筆サービス「事例侍」を利用してMy Redmineの事例を紹介 導入事例コンテンツ取材&執筆サービス「事例侍」を利用してMy Redmineの事例を紹介株式会社スプーの「事例侍」を利用。経験豊富なエディターさん、ライターさんによる編集でより良い導入事例に。 |
|
 仮想マシン+Windowsの代わりにAmazon AppStream2.0を使ってみるのはどうでしょう? 仮想マシン+Windowsの代わりにAmazon AppStream2.0を使ってみるのはどうでしょう?MacでWindowsアプリを動作させるアイデアの一つとしてAppStreamを使ってみました。 |

|
 オープンソースカンファレンス 2022 でセミナー発表しました オープンソースカンファレンス 2022 でセミナー発表しましたOSC 2022オンラインFallで「はじめてのプロジェクト管理ツール〜Redmine超入門〜」を発表。 |
|
 Redmineで構築されている国民年金基金連合会の「他年金調査 事業所回答システム」を調べてみた Redmineで構築されている国民年金基金連合会の「他年金調査 事業所回答システム」を調べてみたRedmineを利用して構築されている国民年金基金連合会の「他年金調査 事業所回答システム」を調べてみました。 |

|
プロジェクト管理SaaS「My Redmine」が「GitHub連携機能」を提供開始 GitHubのコード管理と、Redmineの柔軟なチケット管理を両立 |
|
|
夏季休業のお知らせ (8/13〜14休業) 2026/8/13(木)〜8/14(金)は夏季休業とさせていただきます。 |

|
プロジェクト管理SaaS「My Redmine」の「IPアドレスフィルター」で登録可能な「IPアドレス数」の上限を大幅に引き上げ IPアドレスによる制限の上限が、エンタープライズプランでは従来の5倍となる2,000個まで、スタンダード・ミディアムプランでは2倍の200個に引き上げ |

|
Redmineのクラウド版「My Redmine」に大容量1.5TBの「エンタープライズ1.5TBプラン」が新登場! オープンソースのプロジェクト管理ソフトウェアRedmineのクラウド版「My Redmine」に、月々40,000円(税別)の定額で1.5TB、2,000ユーザーまで利用できる大容量プランが登場。 |

|
Redmineの最新情報をメールでお知らせする「Redmine News」配信中 新バージョンやセキュリティ修正のリリース情報、そのほか最新情報を迅速にお届け |