インターネット上の技術・知識を活用してよりよい社会の実現を目指すインターネットサービス企業です。
ファーエンドテクノロジー株式会社

岩石です。 今年の2月は例年より寒かったのか自宅の梅の開花が遅れています。やっと花が咲き始めたのですが、花を愛でる季節になると悩ましいのがスギ花粉とか黄砂とか。 感染症対策とは別の理由でマスクをしているので、屋外で着用していることも多いです。 ウィルスも花粉も見えたら避けるのにとか思うのですが、それはそれで怖くて外を歩けないかもしれないですね。困った困った。
SPFやDKIM、DMARCの設定ができていなかったり不適切であったりしてメールの配送ができない、という話を見かけるようになりました。
2024年の始めから、GmailやYahoo.comなどのメールサービスで、一定数のメールを配信するドメインについてDMARC設定ができていないメールの配送に規制をかける、という取り組みが発表され、これらの迷惑メール対策の認知が広がったと感じています。
参考: クレジットカード会社等に対するフィッシング対策の強化を要請しました (METI/経済産業省)
SPF, DKIM, DMARC とは、それぞれの技術の細かな説明は省きますが、
という組み合わせで、詐称されたメールの配送を防ぐ仕組みです。
最終的にはDMARCの設定次第になるので、SPFなどの認証に失敗していても、DMARCにて配送を許可していれば配送はされます。 DMARCを導入することになったら、導入当初はすべて配送できる設定にして配送トラブルを避け、配送状況の分析を経て制限を設け、認知していない配送(詐称メール)を防ぎます。
詐称メールは、不適切な広告メールやフィッシングメールに利用されることがあり、自組織のメールアドレスが利用されセキュリティートラブルなどに巻き込まれないためにも、適切に設定しないといけません。
しかしながら詐称メール対策の難しいところは、詐称メールの配送に自分たちが全く関与していないところです。 認知していないメール配送は、自分たちが把握しているメールサーバーを経由しませんので、送信時に自分たちが検知することはできません。
参考: フィッシング対策協議会 Council of Anti-Phishing Japan | 報告書類 | 協議会WG報告書 | 送信ドメイン認証技術「DMARC」の導入状況と必要性について
DMARCの仕組みでは、認証の状況などをメールを受け取った側からレポートとして送信側が受け取ることができます(レポート送信の仕組みを備えているサーバーやサービスのみですが)。 このレポート(RUAレポート)は、1日単位で受け取ったメールの認証状況等を、XML形式で(通常ZIPやGZIPで圧縮されて)指定のメールアドレスに報告(ファイル添付)されます。 (RUFレポートという詳細レポートもありますが、今回は触れません)
とてもありがたい機能ですが、少々取り扱いが煩雑です。 メールに添付されたファイルをダウンロードして、圧縮ファイルを解凍して、そして出てきたものはXML形式...。 しかも、メールを受け取った側からバラバラに1日単位で送ってくるため、統計を取るのが難しいです。 配送の制限を設けるためには分析が必須と思いますので、簡単に管理する方法がないか、ずっと考えていました。
XML形式のレポートファイルを解析するサービスはいくつかあり、無料のものもあります。ただし、そのサービスが利用しても安全なものかどうか判断が難しかったり(調べること自体が手間ですよね)、そもそも1ファイルずつ解析にかけるのも面倒だったり。なにより外部のサービスにファイルをアップロードすること自体が障壁が高いと感じます。
そこで、自動的にメールを受け取り、添付ファイルの内容を分析用に見やすくすることを考えてみました。 不要になったり本採用になったりしたときの削除や再構築を考慮し、できればAWSのサービスに集約したいと思い、構成などを検討してみました。 まだ試行段階ではありますが、その仕組みなど紹介します。
※ 今回使用したレポート(そしてその中で報告されている件数など)は、弊社の業務で使用しているものではありません。プライベート使用のドメインでのレポートをサンプルとして使用しています。
まず、DMARCレポートを受け付ける専用のメールアドレスを決めます。
今回は自動処理を想定しており、誰にも紐づいていないメールアドレスにDMARCレポートを送ってもらいたいので、サブドメインを作り、そのアドレスにレポートを送ってもらうようにします。
不要になった時に、あとから誰でも判断ができるようにわかりやすい名前(例えば reports@dmarc.[自社ドメイン] など)にすると良いと思います。
今回は仮に dmarc-reports@ses.[自分のドメイン] ということにします。
今回の仕組みはAWSのサービスで完結しようと考えています。Amazon SES はメールの受信ができますので、このサービスで上記のメールアドレスを使用することとします。
次に、Amazon S3に今回の用途向けのバケットを作成します(仮に iwaishi-dmarc-reports とします)。
そして、メール受信用と分析レポートの保存用にそれぞれのプレフィックス(フォルダ)を作成します。
今回はメール受信用に emails 、分析用に processed としました。
次に、Amazon Route53でサブドメインの設定をします。
Route53で設定しなくても他社のDNSサービスやサーバーで動作するDNSサーバーでも実現可能ですが、Route53でサブドメインを管理すると、この後の作業に関連して処理が楽になります。
まずホストゾーン=(サブ)ドメイン ses.[自分のドメイン] を作成します。
するとNSレコードとして4つのホストが設定されます。このNSレコードを [自分のドメイン] のドメイン情報を管理するDNSサーバー(やRoute53)の方に ses.[自分のドメイン] のNSレコードとして登録します。
そして、Amazon SESのEメール受信を設定します。
メールアドレスを登録する前にID登録が必要で、その際にドメインの所有者確認などがあります。
この(サブ)ドメインにはメールサーバーがありませんので、ドメインで証明する方を選択します。
続いて、この(サブ)ドメインのサーバーのDKIM設定やMXレコードの設定をしますが、DKIMについてはRoute53にドメイン情報があれば自動的に登録することができます。
MXレコードには 10 inbound-smtp.ap-northeast-1.amazonaws.com と設定します(SESを東京リージョンで使用する場合)。
その他の内容についてはマネジメントコンソールのガイドでなんとかなると思います。
つまづいたら公式ドキュメントや先人たちのナレッジを参考に。
Amazon SESのEメール受信にて、決定したメールアドレスの保存先として作成したバケットの emails プレフィックスを指定します。
今回は下記のように設定しました。
| 項目 | 設定内容 |
|---|---|
| 受信ルールセット | dmarc-reports |
| 受信ルール - 受信者の条件 | メールアドレス( dmarc-reports@ses.[自分のドメイン] ) |
| 受信ルール - アクション | Amazon S3バケットに保存 |
| 受信ルール - 保存先バケット | 作成したバケット( iwaishi-dmarc-reports ) |
| 受信ルール - プレフィックス | 受信用プレフィックス( emails/ ) |
設定が完了すると、S3に AMAZON_SES_SETUP_NOTIFICATION というファイルができていました。
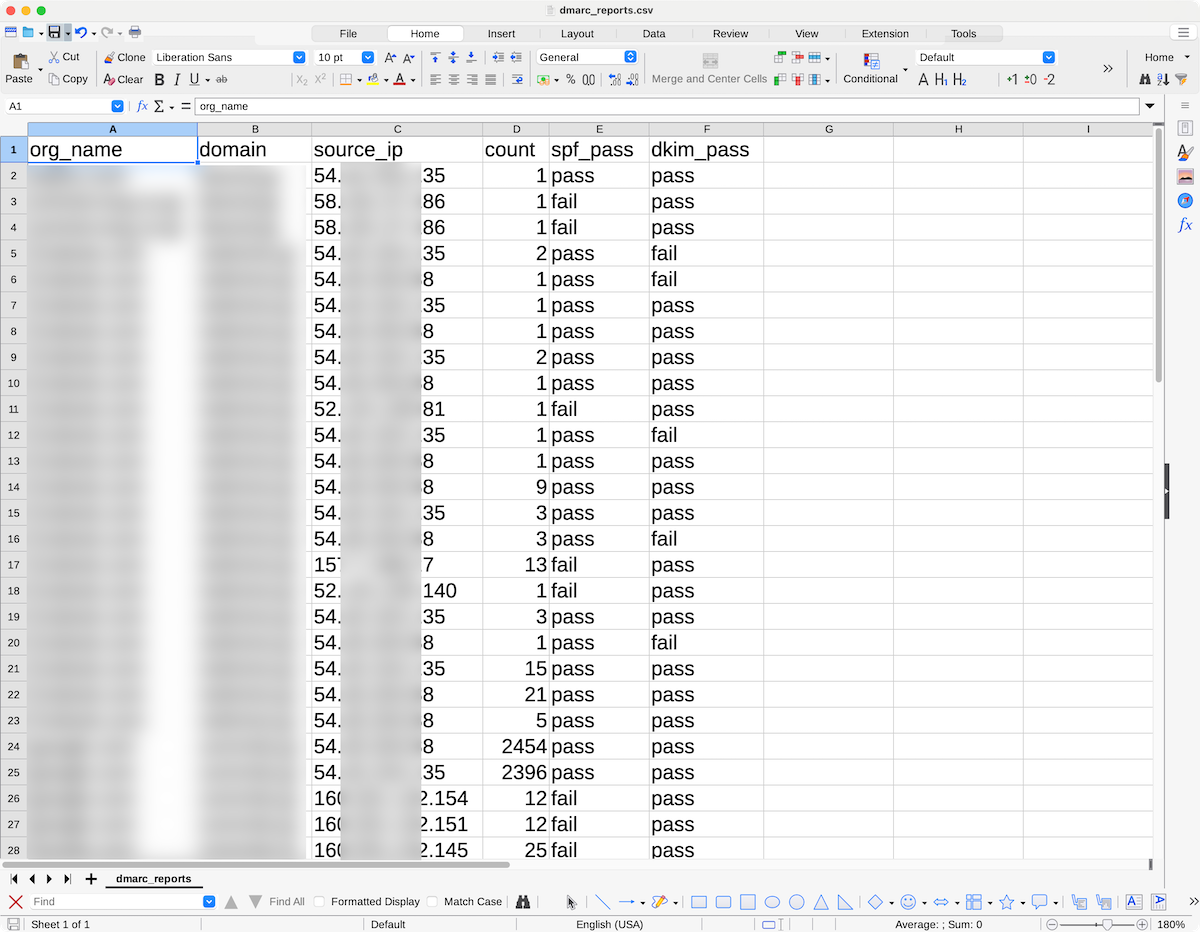
メールを受信したら添付ファイルを解凍し、XMLの内容からCSVファイルに結果を追記するようにします。
AWSに詳しい方なら
「えっ!CSVに追記??? DynamoDBじゃないのかよ!」
って言われそうですが、今回はコスト面や簡易さ、またCSVファイルであれば取り出して何か別のもので集計することも簡単なので、この方法を選びました。
ファイルを展開しCSVデータを追記するところまでをLambda関数で処理します。
いつもはRubyを使ってますが、組み込みではないライブラリを使用するRubyスクリプトをLambdaで管理するためにはちょっとした段取りが必要です(難しいものではないです)。
今回は、簡単にAWSのマネコンで進めたかったので、Pythonを採用しました。
Pythonは不慣れなのでコーディングとコードレビューには複数の生成AIサービスに手伝っていただきました(片方で生成、もう片方でレビュー)。壁打ちを繰り返し、最適化や機能追加などまだ改善の余地はありますが、現時点では下記のようなコードとなっています。
import json import boto3 import email import io import zipfile import gzip import csv from email import policy from email.parser import BytesParser import xml.etree.ElementTree as ET s3 = boto3.client("s3") BUCKET_NAME = "[作成したバケット名(本記事では iwaishi-dmarc-reports )]" CSV_FILE_KEY = "processed/dmarc_reports.csv" def lambda_handler(event, context): """SNS経由で受信したS3イベントを処理""" print("Received event: " + json.dumps(event, indent=2)) for record in event.get("Records", []): sns_message_str = record.get("Sns", {}).get("Message") if not sns_message_str: print("⚠️ SNS message not found in event") continue try: # SNSメッセージをデコード(1回目) sns_message = json.loads(sns_message_str) # SNSメッセージ内の "Records" を取得 s3_records = sns_message.get("Records", []) for s3_record in s3_records: if s3_record.get("eventSource") == "aws:s3": bucket = s3_record["s3"]["bucket"]["name"] key = s3_record["s3"]["object"]["key"] print(f"✅ Processing file from S3 - Bucket: {bucket}, Key: {key}") process_s3_email(bucket, key) else: print("⚠️ eventSource is not aws:s3 or missing:", s3_record) except json.JSONDecodeError as e: print(f"❌ JSON decode error: {e}") except Exception as e: print(f"❌ Unexpected error: {e}") def process_s3_email(bucket, key): """S3からEメールを取得し、添付ファイルからDMARCレポートを抽出してCSVに保存""" response = s3.get_object(Bucket=bucket, Key=key) raw_email = response["Body"].read() # メールを解析 msg = BytesParser(policy=policy.default).parsebytes(raw_email) # 添付ファイルを処理 for part in msg.iter_attachments(): filename = part.get_filename() if not filename: continue print(f"Found attachment: {filename}") content = part.get_payload(decode=True) if filename.endswith(".gz"): xml_data = gzip.GzipFile(fileobj=io.BytesIO(content)).read().decode("utf-8") elif filename.endswith(".zip"): xml_data = extract_zip(content) elif filename.endswith(".xml"): xml_data = content.decode("utf-8") else: print(f"⚠️ Unsupported file format: {filename}") continue if xml_data: append_to_csv(parse_dmarc_report(xml_data)) def extract_zip(data): """ZIPファイルを解凍してXMLを取得""" with zipfile.ZipFile(io.BytesIO(data), "r") as zip_ref: for file in zip_ref.namelist(): if file.endswith(".xml"): return zip_ref.read(file).decode("utf-8") return None def parse_dmarc_report(xml_data): """DMARCレポートのXMLを解析し、CSV形式のデータを生成""" report_data = [] # リストとして初期化 root = ET.fromstring(xml_data) org_name = root.find("./report_metadata/org_name").text domain = root.find("./policy_published/domain").text for record in root.findall("./record"): source_ip = record.find("./row/source_ip").text count = record.find("./row/count").text spf_pass = record.find("./row/policy_evaluated/spf").text dkim_pass = record.find("./row/policy_evaluated/dkim").text # 1レコードずつリストに追加 report_data.append([org_name, domain, source_ip, count, spf_pass, dkim_pass]) return report_data # ✅ リストのリストとして返す def append_to_csv(data): """S3のCSVファイルにデータを追記""" try: # ✅ 既存のCSVデータを取得 response = s3.get_object(Bucket=BUCKET_NAME, Key=CSV_FILE_KEY) existing_data = response["Body"].read().decode("utf-8") except s3.exceptions.NoSuchKey: existing_data = "" # CSVが存在しない場合は新規作成 output = io.StringIO() writer = csv.writer(output) if not existing_data: # ✅ ヘッダー行を追加(初回のみ) writer.writerow(["org_name", "domain", "source_ip", "count", "spf_pass", "dkim_pass"]) else: # ✅ 既存のCSVデータを `output` にコピー output.write(existing_data) # ✅ 新しいデータを追加 writer.writerows(data) # ✅ S3にアップロード(上書きではなく追記) s3.put_object(Bucket=BUCKET_NAME, Key=CSV_FILE_KEY, Body=output.getvalue()) print(f"✅ Updated CSV file in S3: {CSV_FILE_KEY}")
指定のバケット・プレフィックスから送られてきたメールについて、
という処理をしています。
次に、S3にメールが届いたらLambdaを呼び出す設定です。
通知のためにAmazon SNSを使用します。
まずトピックを作成します。
トピックのサブスクリプションとして下記の設定で上記Lambda Functionを指定します。
| 項目 | 設定内容 |
|---|---|
| イベント名 | 任意 |
| プロトコル | Amazon Lambda |
| エンドポイント | Lambda FunctionのARN |
そしてAmazon S3の当該のバケットのプロパティーのイベント通知にて、以下のように設定します。
| 項目 | 設定内容 |
|---|---|
| イベント名 | 任意 |
| プレフィックス | emails/ |
| イベントタイプ | すべてのオブジェクト作成イベント |
| 送信先 | SNSトピック |
| SNSトピックを特定 | SNS トピック ARN を入力 |
| SNSトピックARN | 上記SNSトピックARN |
文字にすると多くの項目があり、やれやれという感じですが実際にはそれほど込み入った内容や連携はありません。
ここまでできたら、動作テストとして今までに届いているDMARCレポートが含まれたメールを、今回決定したメールアドレスに転送してみてください。
数秒後には emails プレフィックスにメールが保存され、 processed プレフィックスの中に dmarc_reports.csv というCSVファイルが作成されていると思います。
CSVファイルが作成されていたらダウンロードし、開いてみて、期待通りの内容で作成されているか確認してみてください。
うまくいっていないときは、Lambdaの処理に原因があると思います。CloudWatchのロググループ( /aws/lambda/[Lambda Function名] )を調べて、思いの通りCSVファイルが更新されるように修正してみてください。
最後に、DMARCのXMLレポートが今回のメールアドレスに届くように設定します。
DMARCの設定はDNSの仕組みを使用していますので、これを変更します。
DNSサーバもしくはRoute53の設定変更ですね。
DMARC用のレコードは _dmarc というTXTのレコードです。
"v=DMARC1;〜" で始まる内容について rua=mailto:dmarc-reports@ses.[自分のドメイン] と記載します。
DNSにて設定しますので、反映には時間がかかりますし、そもそもこのメールは頻繁に届くものではありませんので、1日〜数日は放置して待つことになります。 数日経って、S3のメール保存用プレフィックスに保存ファイルが増えていれば成功ですね。
ここまでできていれば、CSVファイルにはどんどん行数が増えていると思います。
CSVファイルを取り出してExcelなどのスプレッドシートで分析もできます。
今回はAWSのサービスに閉じ込めたかったのと、見栄えや更新処理を考えてQuickSightを使うことにします。
QuickSightについては設定等が文字であらわしにくいので、細かな設定については今回は触れません。
公式ドキュメントや他のリソースを参考に進めてください。
GUIツールなので視覚的になんとか進めることができると思います。
今回は、個人管理のAWSアカウントで作業を進めたのですが、最近は初めてQuickSightを使用するアカウントでは、Standardプランをマネジメントコンソールで選べないようです。
まだアイデアを試行している段階ですし、コストも考えStandardプランで検証したいところです。
Webで調べてみると下記の記事に出会いました。これを参考に作成しました。
[アップデート] Amazon QuickSight のアカウント作成フローが変わり、なんとスタンダードエディションが選択できなくなってました | DevelopersIO
AWS CLIを使用するのに認証キーを設定するのが好みではないので、最近はCloudShellを使用することが多いです。
この場合 –profile の指定は不要です。
次の内容のファイルをCloudShell内に作成します。
{
"Edition": "STANDARD",
"AuthenticationMethod": "IAM_AND_QUICKSIGHT",
"AwsAccountId": "[AWSのアカウントID]",
"AccountName": "[QuickSightのアカウント名]",
"NotificationEmail": "[自分のメールアドレス]"
}
そして次のAWS CLIコマンドで作成します。
> aws quicksight create-account-subscription --cli-input-json file://[上記で作成したJSONファイル]
QuickSightが使えるようになったら、次はデータセットの指定です。
Amazon S3の iwaishi-dmarc-reports バケットへのアクセス権を適切に設定し、 processed/dmarc_reports.csv をデータソースとして使えるようにします。
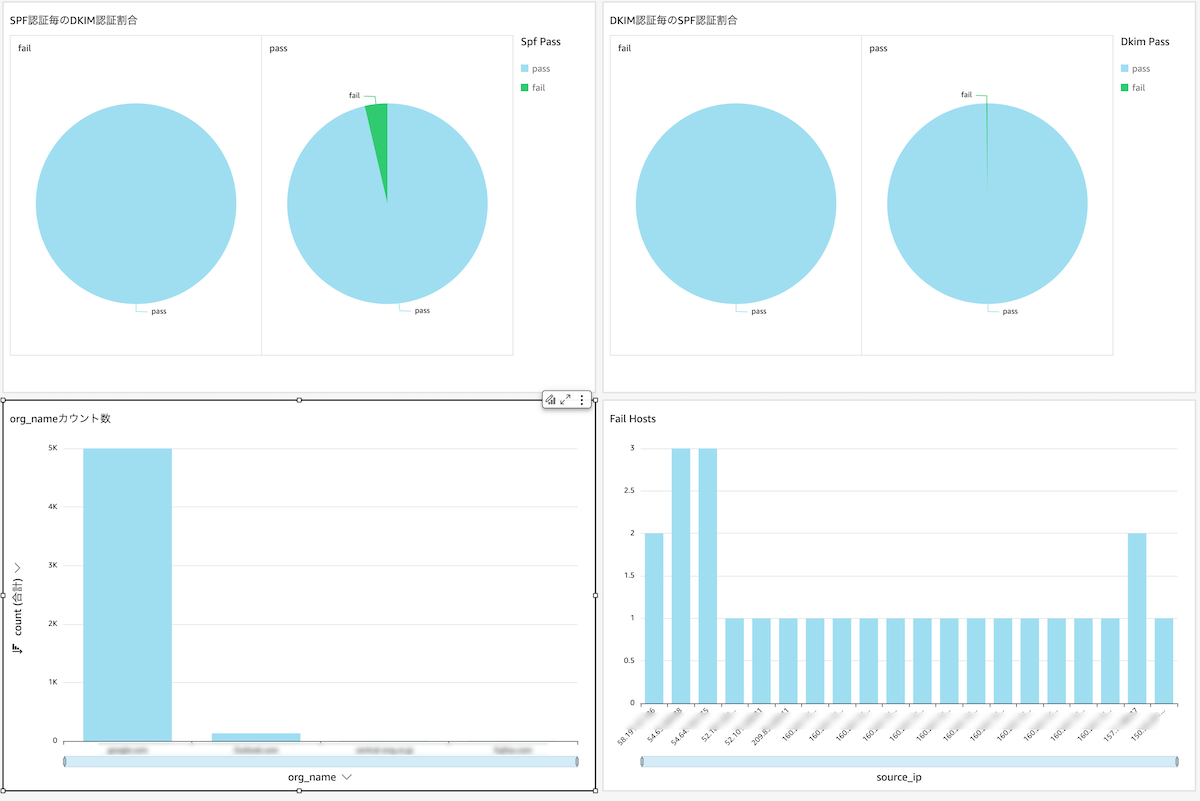
ここまできたらあとは自由にグラフなどが作れます。
認証結果で円グラフを書いたり、失敗したソースIPで棒グラフを書いたり...
とりあえず簡易的に分析ができるようになりました。
今回の設定では、データセットの内容はあえて自動更新するようにはしていませんので、確認する時にQuickSightのデータセットの画面から更新し最新情報にする必要があります。
今回は触れませんが、このままではS3への保存容量が増えるだけ増え、僅かずつですが上限なく費用が増えていきます。
S3へ保存するメールを定期的に削除するとか(Lambdaのログも然り)、CSVの行数も古いものは削除するなどの処理を入れた方が良さそうです。
また今回の内容でざっくりとした統計はわかるようになりましたが、詳細については別の切り口で調べる必要があります。
コードも書き換えができますし、より発展的に詳細分析ができるように作り変えていくのも良さそうです。
そして大規模に活用したり詳細分析することを見すえ、CSVファイルではなくDynamoDBに保存し、スプレッドシートではなくAthenaを使って分析することを考えてみたいと思います。
DMARCレポートの分析ツールの試作途中ですが、割と簡単にできそうなのでご紹介させていただきました。

|
 AWS Glue のクローラーを使用して Application Load Balancer(ALB)のログからデータカタログを作成し、Amazon Athena で検索してみた AWS Glue のクローラーを使用して Application Load Balancer(ALB)のログからデータカタログを作成し、Amazon Athena で検索してみたApplication Load Balancer のログを見やすくするために、Glue と Athena を利用してクエリーでログを検索できるようにしました。 |

|
 山陰セキュリティ交流会 - 202411 開催レポート 山陰セキュリティ交流会 - 202411 開催レポート2024年11月9日に開催した山陰セキュリティ交流会 - 202411の開催の様子をお伝えします。 |

|
AWS Amplify Gen2 を使ってみた感想 Amplify Gen2を使った初歩的な検証を行い、サンドボックス機能やCDKベースの構築が開発効率を向上させると感じました。 |
|
R言語でRedmine APIのJSON出力を読んでみる Redmine REST APIを使ったJSON形式のデータをR言語で処理してみます。 |
|
 AWSを使用したメール通知処理を改善しています AWSを使用したメール通知処理を改善していますAWSを使用したメール通知がうまくいかない現象を調査し改善を行いました。 |

|
オープンソースカンファレンス2026 Shimane(7/11開催)登壇・ブース出展 2026年7月11日(土)に松江テルサ(島根県松江市)で開催される「オープンソースカンファレンス2026 Shimane」に登壇・ブース出展します。 |

|
プロジェクト管理SaaS「My Redmine」の「IPアドレスフィルター」で登録可能な「IPアドレス数」の上限を大幅に引き上げ IPアドレスによる制限の上限が、エンタープライズプランでは従来の5倍となる2,000個まで、スタンダード・ミディアムプランでは2倍の200個に引き上げ |

|
2026年7月8日 オライリー本の全冊公開日のお知らせ(もくもく勉強会も同時開催) ファーエンドテクノロジーが所蔵するオライリー本(全冊)公開日のご案内です。公開日には「もくもく勉強会」も同時開催します。 |

|
Redmineのクラウド版「My Redmine」に大容量1.5TBの「エンタープライズ1.5TBプラン」が新登場! オープンソースのプロジェクト管理ソフトウェアRedmineのクラウド版「My Redmine」に、月々40,000円(税別)の定額で1.5TB、2,000ユーザーまで利用できる大容量プランが登場。 |

|
Redmineの最新情報をメールでお知らせする「Redmine News」配信中 新バージョンやセキュリティ修正のリリース情報、そのほか最新情報を迅速にお届け |