インターネット上の技術・知識を活用してよりよい社会の実現を目指すインターネットサービス企業です。
ファーエンドテクノロジー株式会社

岩石です。会社から貸与されるPCが MacBook Pro (15-inch, 2016) から MacBook Pro(14-inch, 2021) へと新しくなりました。
会社で初めてのM1チップ(M1 Max)で、人柱的な感じもあるのですがいまのところ問題なく使えています。一番楽しみにしているのがAdobe Premiere Proでの動画エンコーディングの時間短縮なのですが、まだあまり長時間の動画を触ってないので、「長めの動画, come on!」といつもとは違う気持ちの日々です。まあ短い方が嬉しいですけどね。
私は開発者(プログラマー)でもなければ、データサイエンティストでもなく、統計解析分野は全くの素人です。しかしながら膨大なデータを取り扱うことが容易になった昨今では、既知の情報を元にした分析結果を用いて話をするのが相応しい場面が多くなりました。機械学習を使用した分析サービスも利用しやすくなってきましたが、解析ツールとどちらを使うのが望ましいかわからない時があります。統計解析と機械学習の違いについては以下のサイトの記事がとてもわかりやすく参考にさせていただきました。
素人解釈では 統計解析はデータの解釈 に、 機械学習は予測 に主眼が置かれていると感じました。どちらがより良いというものでも無いので、取得データの量・質・利用目的などでどちらも使えるようになっていると良いですね。
BI(Business Inteligence: データ分析などによるビジネス上の意思決定サポート)などに特化したサービスがAWSなどのクラウドで利用することができますが、もう少し基礎的なトライをやってみたくなりローカルでの環境を求め R を試すことにしました。
R言語は主に分析で使用することを目的として作られているオープンソースのプログラミング言語です。アルファベット1文字の言語ということでC言語などと関連があるのかと思いましたが、AT&Tベル研究所が開発したS言語が参考にされているそうです。詳しい経緯などは調べてません。ご興味あればこちらで。
R言語の日本語の情報については三重大学の奥村教授の研究室サイトが日本語では最も充実しているものの一つで参考にさせていただきました。そのほかにもインターネット上に多くの情報があり、また書籍も多数発刊されています。
Rのインストールなどの詳細情報はR言語プロジェクト公式サイトやインターネット上の記事をご参照ください。今回は手法の紹介はしません。私はmacOSを使用しており、通常アプリケーションの管理はHomebrewで行なっているため、同様にインストールをすることを考えたのですが、ネット上の記事などで導入に苦労した話を見かけることがありました。あえて困ってみるのも学びではあったのですが、早く使ってみたかったので公式サイトの情報の通り公式のダウンロードサイトからmacOS用パッケージを取得・インストールを行いました。特筆する注意点など全くなく、何事もなく使えるようになりました。
当社にはオライリー・ジャパンさんの書籍がたくさんあります(セミナールーム - ファーエンドテクノロジー株式会社)。オライリー・ジャパンの書籍にはRに関連するものが比較的多数出版されています。そのうち初学者向けのものとしては下記のものがあります。
どちらも初学者向けですが、1はRのIDEであるRStudio(OSSの他、サポートの付いた有料製品版もあり)についての内容です。できることはIDEでなくても同じなのでどちらに書かれている内容も使用することができます。
このほかにもR関係の書籍は約10冊程度あり、今後も学習していくには題材に困らなさそうです。
学びを行なっていく上ではデータの取得が大きな課題となります(機械学習含め分析作業ではこれがもっとも大変)。オープンデータなど自由に使える実データもあり、これを使用するのも良いかと思いましたが、私はテキストマイニングを行うことにしました。WebサイトやSNSなど現在の世の中ではテキストデータが溢れており入手が楽そうな気がしました。私の業務では膨大なログの存在もあり活用にも向いていそうだとも感じました。
当社のオライリー図書館にはRによるテキストマイニングという書籍がありましたが、R初学者そしてテキストマイニング自体もこれからという私には少し階段を飛ばした感じがありましたので、別途次の書籍を購入しました。
R初学者向けの内容でテキストマイニングについての学びについての書籍です。同書ではインストールや操作・言語の基礎などに続いて、テキストマイニング実践の最初のトライとして 形態素解析 が書かれています。
形態素解析とは文章を意味のある単位に分解し、その分割された文字の品詞などを判別する処理です。英語などほとんどの単語がすでに分割されている言語では比較的難しくないのかもしれないですが、日本語は漢字仮名まじりで句読点でのみ文字分割されている言語であり、形態素解析を使用しなければ翻訳や検索などに多くの支障が発生します。
形態素解析のイメージですが、「 私は公園で本を読みます。 」を解析すると、
私(代名詞)
は(助詞)
公園(名詞)
で(助詞)
本(名詞)
を(助詞)
読み(動詞)
ます(助動詞)
。(記号)
に分割し品詞などの情報を判別します。
日本語に対応した形態素解析といえばMecabがとても有名です。オープンソースの形態素解析エンジンで多くのシステムで利用されているそうです。解析素人の私も存在は知ってました。RでMecabを使用するためにはRMecabライブラリを読み込み実行します。RMecabはCRANというRの標準アーカイブには登録されていないため、公式サイトよりパッケージを取得しインストールする必要があります。
先の形態素解析の例を実行してみます。
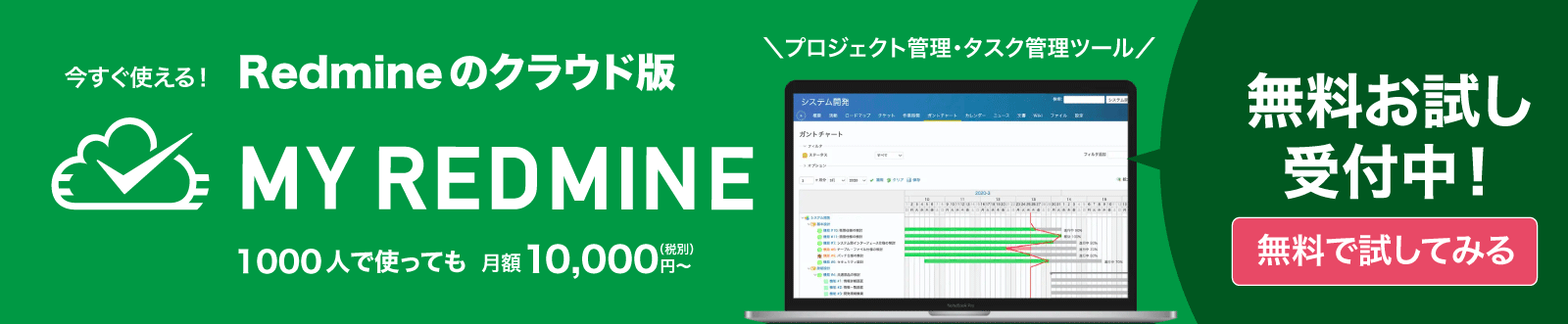
> library(RMeCab) #実行の最初にのみライブラリの読み込みが必要 > text <- "私は公園で本を読みます。" > result <- RMeCabC(text) #この時点で解析は完了 > resultlist <- unlist(result) #表示の都合でベクトル形式(ざっくり言うと配列みたいなもの)に変換 > resultlist 名詞 助詞 名詞 助詞 名詞 助詞 動詞 助動詞 記号 "私" "は" "公園" "で" "本" "を" "読み" "ます" "。" >
簡単な形態素解析ができました。
少し長めの文章中の単語の頻出状況を調べてみます。引用元は当ブログ今年4月7日の私の記事です。
> sampletext <- "そして2021年の開催については、現地開催とオンラインでのハイブリッド開催という方針が早期に出されました。家族やその他含め私個人の周囲の状況では、まだまだ横浜に出かけるには課題も多く、当初よりオンラインでの参加を予定していましたが、昨年12月に現地開催は中止との決定がされました。開催方法決定までにはアンケートなども行われ、新型コロナウィルスの感染状況だけでなくアンケートの結果などもふまえての決定だったのだろうと感じています。 + オンラインでの参加となりましたが、オフライン開催と比較し出展社数が少なく、正直とても残念な感想を持ちました。背景として想像したことは、多くの企業でオンラインでの製品紹介やウェブセミナーなどを行っており、展示会というイベントでなくても催しが実践できる状況になっていることは理由の一つかなと感じました(私個人の想像ですので事実とは異なるかもしれません)。もちろん初めてのオンライン開催ということで、運営の大変さというのも理由としてあるかもしれません。 + オンラインでの開催で出展企業数が少ないことは残念でしたが、オンラインのおかげで参加することができる(都合や移動などを気にする必要がない)ことや、直接人と話さなくてもいろいろ見ることができるという気軽さなどのメリットもあります(スタッフの方々を気にせずジックリ見て回りたい時ありますよね!)。 + 都合や費用的に現地に行けない場合もありますし、移動については気にしなければいけないことがある現在の状況ですので、 出展者数も多く・オンラインで参加も可能・必要に応じて質問などできる そんな展示会・イベントが開催できるようになると良いですね。" > sampletext.result <- RMeCabC(sampletext) > sampletext.list <- unlist(sampletext.result) > table.words <- table(sampletext.list) > sort.table.words <- sort(table.words, decreasing = TRUE) > head(sort.table.words, 10) sampletext.list の 、 が で に は も た て と 23 14 13 13 13 10 10 9 9 9 >
「の」という単語を最も多く使用しているようですね。
単語の出現数をみてもあまり面白くなかったので、品詞での統計を出力してみます。
> table.parts <- table(names(sampletext.list)) > sort.table.parts <- sort(table.parts, decreasing = TRUE) > head(sort.table.parts, 10) 助詞 名詞 動詞 助動詞 記号 形容詞 副詞 接続詞 連体詞 134 133 47 42 32 6 5 1 1 >
助詞と名詞がほぼ同数。多少は面白くなったかな?
RMeCabには頻度分析用の関数RMeCabFreqがあるのでこれを使ってより簡単に処理をしてみます。毎回テキストを変数に代入するのも大変なのでファイルから読み込みます。当ブログ今年9月15日の私の記事からhtmlタグなどを取り除き、テキスト部分だけを抜き出したファイルを用意しておき、これを読み込みました。
> freqresult <- RMeCabFreq(file.choose()) # ファイル選択ダイアログが表示 file = /Users/iwaishi/Documents/education.md length = 501 > head(freqresult, 10) Term Info1 Info2 Freq 1 いつも 副詞 一般 1 2 ごく 副詞 一般 1 3 できるだけ 副詞 一般 1 4 どうしても 副詞 一般 1 5 ほとんど 副詞 一般 2 6 ほぼ 副詞 一般 1 7 よく 副詞 一般 1 8 常に 副詞 一般 1 9 改めて 副詞 一般 1 10 既に 副詞 一般 1 >
一番左の数は出力結果のIDなので、あまり意味は無いです。Termが単語、Info1が品詞の大分類、Info2が品詞の小分類、Freqが出現数です。
これをFreqで降順ソートして上位の結果を表示します。
> freqsortresult <- freqresult[order(freqresult$Freq, decreasing = TRUE),] > head(freqsortresult, 10) Term Info1 Info2 Freq 62 の 助詞 連体化 104 70 する 動詞 自立 66 40 て 助詞 接続助詞 62 59 を 助詞 格助詞 62 495 、 記号 読点 61 491 。 記号 句点 55 24 ます 助動詞 * 51 46 で 助詞 格助詞 48 31 は 助詞 係助詞 46 17 た 助動詞 * 42 >
やはり「の」は多いですね。
助詞とか見てもつまらない(助詞に失礼!)ので名詞で絞り込みます。
> noun <- freqsortresult[grep("名詞", freqsortresult$Info1),] > head(noun, 20) Term Info1 Info2 Freq 456 こと 名詞 非自立 20 201 研修 名詞 サ変接続 15 190 教育 名詞 サ変接続 13 256 オンライン 名詞 一般 12 459 の 名詞 非自立 12 343 社内 名詞 一般 9 461 よう 名詞 非自立 9 162 参加 名詞 サ変接続 8 330 業務 名詞 一般 8 457 ため 名詞 非自立 8 211 記録 名詞 サ変接続 7 344 社員 名詞 一般 7 382 今回 名詞 副詞可能 7 432 化 名詞 接尾 7 151 使用 名詞 サ変接続 6 174 対応 名詞 サ変接続 6 191 機能 名詞 サ変接続 6 377 私 名詞 代名詞 6 447 者 名詞 接尾 6 467 方 名詞 非自立 6 >
ブログの記事から想定されるような単語が上位に出てくることがわかります。当然の結果ですが面白いですね。(「の」という名詞って何ですかね?)
学びはこれより先のところまで進んでいますが、どうしてもトライの説明として解説が多くなりそうなのでブログではここまでのところを紹介させていただきます。
同書ではこのあと更なる頻度分析やデータ間の関連性の解析、英文テキストの分析などが学べます。分析データの準備が簡単で、またデータによる結果の違いなども見られるので、初学としてテキストマイニングを試すのはとても良い選択だった気がします。
R言語についてはインストールも使い方も簡単で、解析を学ぶのにはとても良いツールです。いろいろ調べるより、もっと早く使ってみるべきでした。解析で使用するツールとしては有償のものも含め様々あるようですが、無料でかつ簡単に導入でき情報も多いR言語はお試しとしても初歩を学ぶにしてもお勧めできるツールだと感じました。
私個人としてはログの解析などにテキストマイニングの手法を踏まえて使っていきたいと考えています(ログには形態素解析は使わなさそうですね)。また今回は特定内容の文字のみが対象でしたが、今後データレイクなどを使用しBIやシステム運用に活かせるトライができるようになりたいです。ツールは既に揃っていますし、学ぶ方法も準備されているのであとは「やる気」だけですね!
良い時代になりました!

|
 RubyとGoogle Cloud Vision APIで光学式文字認識(OCR)を試してみました RubyとGoogle Cloud Vision APIで光学式文字認識(OCR)を試してみましたローカルにある画像から文字情報や、単語の位置情報(座標情報)を取得してみました。 |

|
 通信制大学を卒業しました 通信制大学を卒業しました通信制大学を卒業。会社の学費補助の制度を利用して通信制短大・大学で勉強しました。 |

|
 Webレターで文書の発送を簡単に Webレターで文書の発送を簡単に印刷や封入の必要がない日本郵便のサービス「Webレター」で文書発送の手間を大幅に削減できました。 |

|
 Redmineベースのプロジェクト管理サービス「Planio」日本進出5周年 Redmineベースのプロジェクト管理サービス「Planio」日本進出5周年ファーエンドテクノロジーがサポート&プロモーションを行う「Planio」が日本進出5周年。 |
|
 集合研修をオンライン化してみたぞ! 集合研修をオンライン化してみたぞ!今まで集合研修形式で行っていた教育をSlackとGoogle Formでオンライン化してみました。 |

|
REDMINE JAPAN vol.5(6/26開催)に弊社代表の前田が基調講演に登壇 オープンソースのプロジェクト管理ソフトウェア Redmine の日本最大級のRedmineイベント「REDMINE JAPAN vol.5」に弊社代表でRedmineコミッターの前田剛が基調講演に登壇します。 |

|
Redmineのクラウド版「My Redmine」に大容量1.5TBの「エンタープライズ1.5TBプラン」が新登場! オープンソースのプロジェクト管理ソフトウェアRedmineのクラウド版「My Redmine」に、月々40,000円(税別)の定額で1.5TB、2,000ユーザーまで利用できる大容量プランが登場。 |

|
2026年6月13日 オライリー本の全冊公開日のお知らせ(もくもく勉強会も同時開催) ファーエンドテクノロジーが所蔵するオライリー本(全冊)公開日のご案内です。公開日には「もくもく勉強会」も同時開催します。 |

|
My Redmine 2026 夏アップデートのお知らせ(RedMica 4.1対応) 2026年6月からMy Redmine 2026 夏アップデートを実施します。 |

|
Redmineの最新情報をメールでお知らせする「Redmine News」配信中 新バージョンやセキュリティ修正のリリース情報、そのほか最新情報を迅速にお届け |